
A Practical Framework for AI Governance: Managing Data Sensitivity, Processing Capabilities, and System Boundaries
Many data architects find themselves in a frustrating position:
Responsible for enabling analytics, AI, and data-driven decisions across the organization, but lacking the governance structures that should guide those decisions. There is no clear data classification system. There is no catalog of approved processing systems. And occasionally the CISO appears late in a project to say “No, we can’t do that.”
When governance is unclear, teams operate in uncertainty. Projects slow down. Risk increases. And security teams become the accidental gatekeepers of innovation rather than partners in it.
The good news is that solving this problem does not require building a massive governance program overnight. In practice, organizations can gain clarity quickly by adopting a simple mental model built around three things:
Data Sensitivity Levels
Information Processing Capabilities
System Boundaries
Together, these three elements create a structured way to evaluate how data moves through an organization—and whether that movement is appropriate.
Step 1: Start With Data Sensitivity
Everything begins with understanding the sensitivity of the data being used.
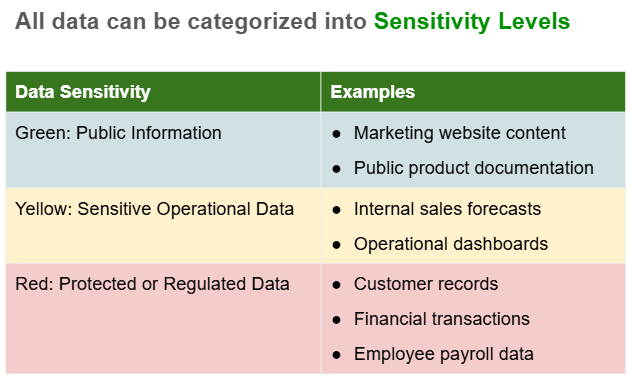
Below is a common starting point where companies create three sensitivity categories.
Green: Data that can be shared openly with little or no risk.
Yellow: Internal information that should remain inside the organization and is not considered personally identifiable information (PII).
Red: Information that could cause harm, legal exposure, or compliance violations if disclosed. Often includes protected information such as PHI, PII, or CUI.
The goal is not perfection—it is creating the habit of asking one simple question:
“What is the sensitivity level of the data I am using?”
Step 2: Identify Information Processing Capabilities
Once data is classified, the next question becomes:
What resources are processing this data?
Many people instinctively think about software systems, but information processing capabilities include both technology and people.
Examples include:
Operational Staff
Data Analysts
External Subject Matter Experts
Excel or BI tools
Internal analytics platforms
External AI services
AI is simply one more information processing capability entering the ecosystem
Different capabilities are suited for different types of problems.
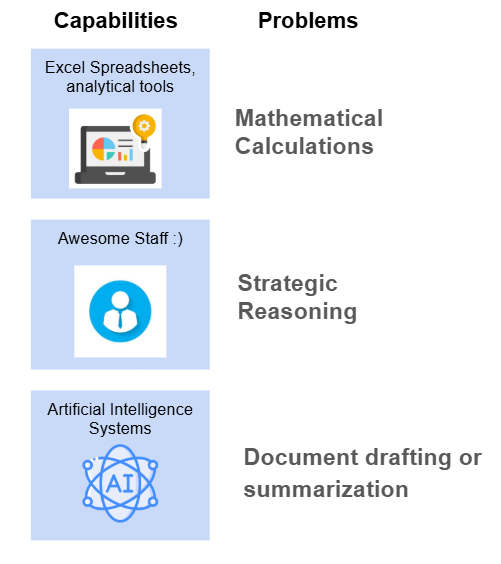
When organizations fail to match the right problem to the right processing capability, they run into common AI issues like hallucinations or unreliable outputs.
Choosing the right capability for the job is one of the simplest ways to reduce risk.
Step 3: Define System Boundaries
The final piece of the framework introduces system boundaries.
Every organization needs to define a boundary between:
Internal systems (systems the organization controls)
External systems (third-party services or vendors)
Data governance becomes critical when information crosses boundaries.
A useful analogy is a passport. Just as a traveler needs authorization to cross national borders, data often needs explicit authorization to move across boundaries.
For example, let's pretend that a company has the following data security position:
Internal systems have access to green and yellow data.
External systems have access to green data by default.
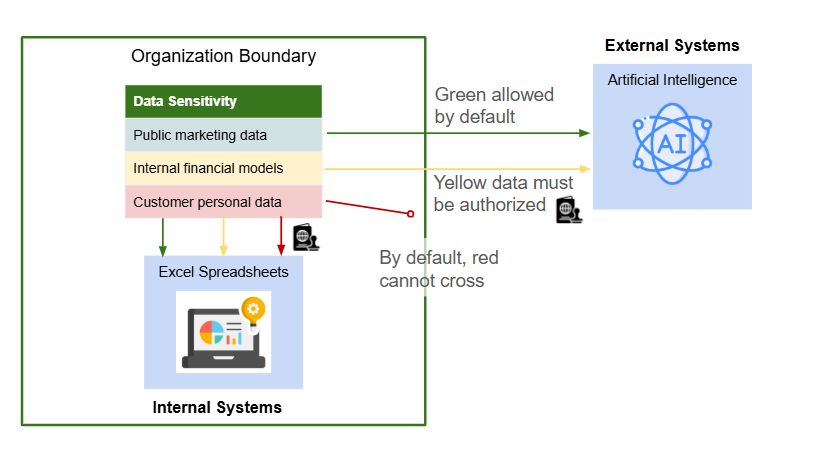
Internal staff will require authorization to process customer personal data on Excel. They will also require additional authorization to send internal financial models to AI.
Each company will write these rules differently, but the basic rules need to exist. Without clear rules, employees may unknowingly share sensitive information with systems that are not approved to process it.
Bringing the Framework Together
The power of this framework to protect a company's data appears when the three components are used together:
In order to reach a target information processing capability, does sensitive data need to cross a system boundary that it is not authorized to cross?
By tracking data sensitivity, processing capabilities, and system boundaries, organizations gain a practical way to reason about how data moves through systems. This framework reduces uncertainty, prevents accidental data leaks, and allows data architects and security teams to make consistent decisions—so innovation can move forward with clarity instead of waiting for last-minute approvals.